github https://github.com/HanSon/vbot
https://github.com/HanSon/my-vbot
修改文件 Example.php
$this->config = $default_config;//array_merge($default_config, $this->config);
修改了一个文件,以实现收到文字回复笔画的功能
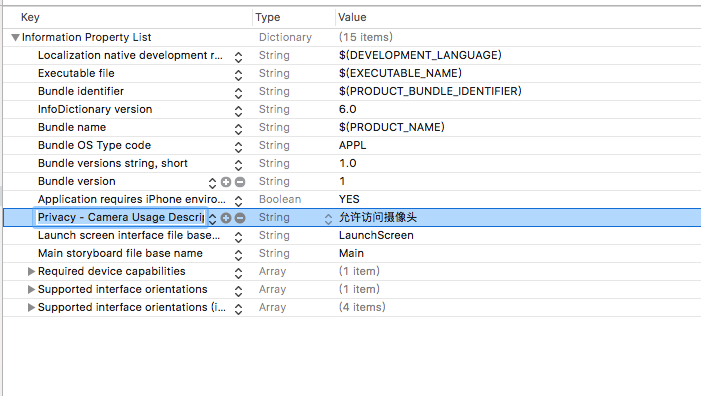
MessageHandler.php
如需主动发起消息请安装swoole,并修改config文件。
pecl install swoole
<?php
namespace Hanson\MyVbot;
use Hanson\MyVbot\Handlers\Contact\ColleagueGroup;
use Hanson\MyVbot\Handlers\Contact\ExperienceGroup;
use Hanson\MyVbot\Handlers\Contact\FeedbackGroup;
use Hanson\MyVbot\Handlers\Contact\Hanson;
use Hanson\MyVbot\Handlers\Type\RecallType;
use Hanson\MyVbot\Handlers\Type\TextType;
use Hanson\Vbot\Contact\Friends;
use Hanson\Vbot\Contact\Groups;
use Hanson\Vbot\Contact\Members;
use Hanson\Vbot\Message\Emoticon;
use Hanson\Vbot\Message\Text;
use Illuminate\Support\Collection;
class MessageHandler
{
public static function messageHandler(Collection $message)
{
/** @var Friends $friends */
$friends = vbot('friends');
/** @var Members $members */
$members = vbot('members');
/** @var Groups $groups */
$groups = vbot('groups');
Hanson::messageHandler($message, $friends, $groups);
ColleagueGroup::messageHandler($message, $friends, $groups);
FeedbackGroup::messageHandler($message, $friends, $groups);
ExperienceGroup::messageHandler($message, $friends, $groups);
TextType::messageHandler($message, $friends, $groups);
RecallType::messageHandler($message);
if ($message['type'] === 'new_friend') {
Text::send($message['from']['UserName'], '客官,等你很久了!感谢跟 vbot 交朋友,如果可以帮我点个star,谢谢了!https://github.com/HanSon/vbot');
$groups->addMember($groups->getUsernameByNickname('Vbot 体验群'), $message['from']['UserName']);
Text::send($message['from']['UserName'], '现在拉你进去vbot的测试群,进去后为了避免轰炸记得设置免骚扰哦!如果被不小心踢出群,跟我说声“拉我”我就会拉你进群的了。');
}
if ($message['type'] === 'emoticon' && random_int(0, 1)) {
Emoticon::sendRandom($message['from']['UserName']);
}
// @todo
if ($message['type'] === 'official') {
vbot('console')->log('收到公众号消息:'.$message['title'].$message['description'].
$message['app'].$message['url']);
}
if ($message['type'] === 'request_friend') {
vbot('console')->log('收到好友申请:'.$message['info']['Content'].$message['avatar']);
if (in_array($message['info']['Content'], ['echo', 'print_r', 'var_dump', 'print'])) {
$friends->approve($message);
}
}
//print_r($message);
$re = 0;
if($message["fromType"] == "Friend"){
$nick = $message['from']['NickName'];
$re = 1;
}
if($message["fromType"] == "Group"){
$nick = $message['sender']['NickName'];
if(@$message['isAt']){
$re = 1;
}
}
if($re ==1 ){
$zi = mb_substr($message["message"],0,1,'utf-8');
$uni = self::unicode_encode($zi);
$var = trim($uni);
$len = strlen($var)-1;
$las = $var{$len};
$url = "http://www.shufaji.com/datafile/bd/gif/".$las."/".$uni.".gif";
//Text::send($message['from']['UserName'], "@".$nick." ".$url);
if(!is_file(__DIR__."/img/".$uni.'.gif')){
$img = @file_get_contents($url);
if(!empty($img)){
file_put_contents(__DIR__."/img/".$uni.'.gif',$img);
Emoticon::send($message['from']['UserName'], __DIR__."/img/".$uni.".gif");
}else{
Text::send($message['from']['UserName'], "@".$nick." 找不到这个字的笔顺".$url);
}
}else{
Emoticon::send($message['from']['UserName'], __DIR__."/img/".$uni.".gif");
}
}
}
private static function unicode_encode($name)
{
$name = iconv('UTF-8', 'UCS-2', $name);
$len = strlen($name);
$str = '';
for ($i = 0; $i < $len - 1; $i = $i + 2)
{
$c = $name[$i];
$c2 = $name[$i + 1];
if (ord($c) > 0)
{ // 两个字节的文字
$s1 = base_convert(ord($c), 10, 16);
$s2 = base_convert(ord($c2), 10, 16);
if(ord($c) < 16){
$s1 = "0".$s1;
}
if(ord($c2) < 16){
$s2 = "0".$s2;
}
$str .= $s1 . $s2;
}
else
{
$str .= $c2;
}
}
return $str;
}
}
itchat 调试完毕后,开始折腾聊天的server
https://ask.julyedu.com/question/7410
首先准备好 torch 环境,然后安装 nn,rnn,async
sudo ~/torch/install/bin/luarocks install nn
sudo ~/torch/install/bin/luarocks install rnn
sudo ~/torch/install/bin/luarocks install async penlight cutorch cunn
下载程序和语料
git clone --recursive https://github.com/rustcbf/chatbot-zh-torch7 #代码
git clone --recursive https://github.com/rustcbf/dgk_lost_conv #语料
git clone --recursive https://github.com/chenb67/neuralconvo #以上两个在此源码进行改进,可作为参考
将 dgk_lost_conv 里的 xiaohuangji50w_fenciA.zip 解压放到外层目录
th train.lua –cuda –dataset 5000 –hiddenSize 100
报错
-- Epoch 1 / 30
/root/torch/install/bin/luajit: ./seq2seq.lua:50: attempt to call field 'recursiveCopy' (a nil value)
stack traceback:
./seq2seq.lua:50: in function 'forwardConnect'
./seq2seq.lua:67: in function 'train'
train.lua:90: in main chunk
[C]: in function 'dofile'
/root/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:150: in main chunk
[C]: at 0x00405d50
修改 seq2seq.lua 如下 (50 – 70 行间)
function Seq2Seq:forwardConnect(inputSeqLen)
self.decoderLSTM.userPrevOutput =
--nn.rnn.recursiveCopy(self.decoderLSTM.userPrevOutput, self.encoderLSTM.outputs[inputSeqLen])
nn.utils.recursiveCopy(self.decoderLSTM.userPrevOutput, self.encoderLSTM.outputs[inputSeqLen])
self.decoderLSTM.userPrevCell =
nn.utils.recursiveCopy(self.decoderLSTM.userPrevCell, self.encoderLSTM.cells[inputSeqLen])
end
--[[ Backward coupling: Copy decoder gradients to encoder LSTM ]]--
function Seq2Seq:backwardConnect()
if(self.encoderLSTM.userNextGradCell ~= nil) then
self.encoderLSTM.userNextGradCell =
nn.utils.recursiveCopy(self.encoderLSTM.userNextGradCell, self.decoderLSTM.userGradPrevCell)
end
if(self.encoderLSTM.gradPrevOutput ~= nil) then
self.encoderLSTM.gradPrevOutput =
nn.utils.recursiveCopy(self.encoderLSTM.gradPrevOutput, self.decoderLSTM.userGradPrevOutput)
end
end
训练之,1080ti 一轮大概 两个多小时。。。 30轮估计需要70小时。妇女节后见了。
eval.lua 的时候报错,不明所以,先放弃这个了,试试别的。
/root/torch/install/bin/luajit: /root/torch/install/share/lua/5.1/nn/Container.lua:67:
In 3 module of nn.Sequential:
/root/torch/install/share/lua/5.1/torch/Tensor.lua:466: Wrong size for view. Input size: 100. Output size: 6561
stack traceback:
[C]: in function 'error'
/root/torch/install/share/lua/5.1/torch/Tensor.lua:466: in function 'view'
/root/torch/install/share/lua/5.1/rnn/utils.lua:191: in function 'recursiveZeroMask'
/root/torch/install/share/lua/5.1/rnn/MaskZero.lua:37: in function 'updateOutput'
/root/torch/install/share/lua/5.1/rnn/Recursor.lua:13: in function '_updateOutput'
/root/torch/install/share/lua/5.1/rnn/AbstractRecurrent.lua:50: in function 'updateOutput'
/root/torch/install/share/lua/5.1/rnn/Sequencer.lua:53: in function </root/torch/install/share/lua/5.1/rnn/Sequencer.lua:34>
[C]: in function 'xpcall'
/root/torch/install/share/lua/5.1/nn/Container.lua:63: in function 'rethrowErrors'
/root/torch/install/share/lua/5.1/nn/Sequential.lua:44: in function 'forward'
./seq2seq.lua:115: in function 'eval'
eval.lua:90: in function 'say'
eval.lua:105: in main chunk
[C]: in function 'dofile'
/root/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:150: in main chunk
[C]: at 0x00405d50
WARNING: If you see a stack trace below, it doesn't point to the place where this error occurred. Please use only the one above.
stack traceback:
[C]: in function 'error'
/root/torch/install/share/lua/5.1/nn/Container.lua:67: in function 'rethrowErrors'
/root/torch/install/share/lua/5.1/nn/Sequential.lua:44: in function 'forward'
./seq2seq.lua:115: in function 'eval'
eval.lua:90: in function 'say'
eval.lua:105: in main chunk
[C]: in function 'dofile'
/root/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:150: in main chunk
[C]: at 0x00405d50
换一个试试 ,tensorflow 的,而且还比较新
git: https://github.com/qhduan/just_another_seq2seq
包含还有一个英译汉的功能。
把之前下载的预料库中的 dgk_shooter_min.conv.zip 解压缩放到 chatbot 目录里
python3 train.py 训练之。
20轮,一轮大概30-40分钟(1070 显卡)
训练完之后执行 Python3 test.py 测试。
注意,tensorflow 在 1.4.1 下。
并修改 test.py 否则 sequence_to_sequence 会报
NotFoundError (see above for traceback): Key decoder/multi_rnn_cell/cell_0/Attention_Wrapper/lstm_cell/bias not found in checkpoint
test(
bidirectional=False,
cell_type='lstm',
depth=2,
attention_type='Bahdanau',
use_residual=False,
use_dropout=False,
time_major=False,
hidden_units=512
)
聊天效果,chatbot_ad 的还行
训练chatbot_ad 的时候,readme 少了一步 train_tfidf.py 。
Input Chat Sentence:我生病了
rl: ['我', '睡', '着', '了', '</s>', '</s>', '</s>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:我想我爱你
rl: ['我', '不', '知', '道', '你', '在', '说', '什', '么', '</s>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:你多大了?
rl: ['你', '看', '上', '去', '不', '错', '</s>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:你好吗?
rl: ['很', '高', '兴', '见', '到', '你', '</s>', '</s>', '<unk>', '<unk>']
Input Chat Sentence:什么时间了
rl: ['你', '要', '去', '哪', '儿', '</s>', '</s>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:去北京
rl: ['维', '克', '多', ',', '过', '来', '</s>', '</s>', '</s>', '</s>', '<unk>', '<unk>']
Input Chat Sentence:去哪?
rl: ['我', '们', '得', '走', '了', '</s>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:走
rl: ['我', '们', '得', '走', '了', '</s>', '</s>', '<unk>']
Input Chat Sentence:走了
rl: ['你', '们', '都', '走', '了', '</s>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:去哪
rl: ['我', '也', '不', '知', '道', '</s>', '</s>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:干啥
rl: ['你', '在', '干', '啥', '啊', '</s>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:他是谁?
rl: ['不', '知', '道', '为', '什', '么', '</s>', '</s>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:你是谁?
rl: ['我', '是', '麦', '克', '墨', '菲', '医', '生', '</s>', '<unk>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:你哎我 吗?
rl: ['我', '有', '话', '跟', '你', '说', '</s>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:你爱我 吗?
rl: ['什', '么', '东', '西', '?', '</s>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:你爱我吗?
rl: ['我', '爱', '你', ',', '宝', '贝', '</s>', '<unk>', '<unk>', '<unk>', '<unk>']
Input Chat Sentence:
chatbot_ad 用 bottle 改造了一个 url api接口用于和 itchat 对接。代码如下。
# -*- coding: utf-8 -*-
"""
对SequenceToSequence模型进行基本的参数组合测试
"""
import sys
import random
import pickle
import numpy as np
import tensorflow as tf
import bottle
sys.path.append('..')
from data_utils import batch_flow
from sequence_to_sequence import SequenceToSequence
from word_sequence import WordSequence # pylint: disable=unused-variable
random.seed(0)
np.random.seed(0)
tf.set_random_seed(0)
_, _, ws = pickle.load(open('chatbot.pkl', 'rb'))
config = tf.ConfigProto(
device_count={'CPU': 1, 'GPU': 0},
allow_soft_placement=True,
log_device_placement=False
)
save_path_rl = './s2ss_chatbot_ad.ckpt'
graph_rl = tf.Graph()
with graph_rl.as_default():
model_rl = SequenceToSequence(
input_vocab_size=len(ws),
target_vocab_size=len(ws),
batch_size=1,
mode='decode',
beam_width=12,
bidirectional=False,
cell_type='lstm',
depth=1,
attention_type='Bahdanau',
use_residual=False,
use_dropout=False,
parallel_iterations=1,
time_major=False,
hidden_units=1024,
share_embedding=True
)
init = tf.global_variables_initializer()
sess_rl = tf.Session(config=config)
sess_rl.run(init)
model_rl.load(sess_rl, save_path_rl)
@bottle.route('/login/<w>', method='GET')
def do_login(w):
user_text = w
x_test = list(user_text.lower())
x_test = [x_test]
bar = batch_flow([x_test], [ws], 1)
x, xl = next(bar)
pred_rl = model_rl.predict(
sess_rl,
np.array(x),
np.array(xl)
)
#word = bottle.request.forms.get("word")
str2 = ''.join(str(i) for i in ws.inverse_transform(pred_rl[0]))
return str2
bottle.run(host='0.0.0.0', port=8080) #表示本机,接口是8080
注意不要聊的太猛,容易被腾讯封了。
[2018-03-12 02:34:54][INFO] please scan the qrCode with wechat.
[2018-03-12 02:35:01][INFO] please confirm login in wechat.
Array
(
[ret] => 1203
[message] => 当前登录环境异常。为了你的帐号安全,暂时不能登录web微信。你可以通过Windows微信、Mac微信或者手机客户端微信登录。
)
[2018-03-12 02:35:03] vbot.ERROR: Undefined index: skey [] []
PHP Fatal error: Uncaught ErrorException: Undefined index: skey in /Users/zhiweipang/my-vbot/vendor/hanson/vbot/src/Core/Server.php:194